这篇文章上次修改于 1927 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
本文已授权微信公众号「玉刚说」独家发布。
大家好,你现在看到的是「Java 混淆那些事」系列文章的第一篇,通过这个系列我想带大家重新认识一下 ProGuard 到底能干什么?最终领悟怎么才能写好混淆规则。所以说这个系列文章的重点将会放到书写 keep 规则上面。我会最大程度用大白话写明白。
首先我们了解一下 ProGuard 到底是什么能干什么?
ProGuard 是可以对 Java 类文件进行压缩、优化、混淆和预验证的工具。
简单解释一下 ProGuard 的功能
- 压缩 (Shrinker):删除无效的类、字段、方法等。
- 优化 (Optimizer):优化字节码,合并方法,删除无用字段等。
- 混淆 (Obfuscator):将类名、属性名、方法名以及字段名混淆为难以读懂的字母,比如a, b, c等。
- 预校验 (Preverifier):对 class 文件进行预检验,确保虚拟机加载的 class 文件是安全并且可以执行的。
我们再来看下一个问题 ProGuard 是以什么样的流程进行工作的。
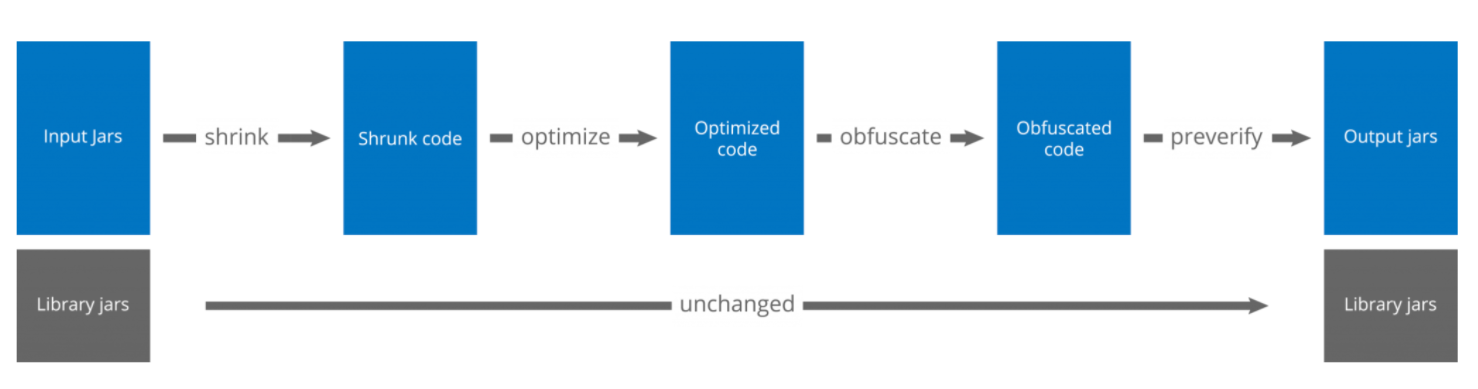
- 压缩阶段
ProGuard 会从「代码入口点」开始递归查找,把用到的类或变量等留下来,没用到的全都删掉。 - 优化阶段
ProGuard 会优化经过压缩阶段留下来的类,比如将外部没有调用的非代码入口点的方法或类改为私有的,又或者把一部分方法改为 final 的,相应的字段改为 static、final,或者把几个方法合并成一个,删除没有用到的参数等等的优化操作。 - 混淆阶段
将代码入口点调用到的类和方法(非代码入口点方法),给他改个名字,比如简短的或者复杂的,这个过程中重命名的字典可以自定义。改完名字后还能保证程序的正常运行逻辑。 - 预校验阶段
在编译版本为 Java ME 或 1.6 以及更高版本时是默认开启的。但编译成 Android版本时,预校验是不必须的。
那么代码入口点到底是什么呢?
好的现在就忘记以上这些废话,我们重点来看第一个知识点「代码入口点」。我们刚才应该也看到了 ProGuard 压缩阶段是从代码入口点开始递归查找用到的代码的。
举个例子:比如你写了一个很方便的下载类,假设需要使用的就这一个方法 new DowonloadClien("url").start() 那么这个方法就应该指定为代码入口点。
ProGuard 怎么知道哪里是代码入口点的呢?
没错这个代码入口点如果我们不告诉 ProGuard,他是不会知道的。那么怎么告诉他呢?我们通过 keep 规则就可以告诉 ProGuard 了,具体用法我们以后文章中具体说,这里就了解一下。
举个例子
下面我们写一个通俗的小例子,配合代码理解一下。看看压缩、优化、混淆这些功能。
//测试代码,如下代码纯属为了测试,除此之外没有任何合理性。
src
-> model
-> ModelA.java
int testA = 2;
public void modelA(int age) {
int a = 1 + age;
int b = testA + age;
System.out.println("print " + b);
}
public void modelB(String name) {
System.out.println("print " + name);
}
-> ModelB.java
public void modelA(String name) {
System.out.println("print " + name);
}
public void modelB(String name) {
System.out.println("print " + name);
}
-> utils
-> UtilsA.java
private static final String UtilA = "utila";
public static void printA() {
System.out.println("print " + UtilA);
}
public static void printB() {
System.out.println("print B");
}
-> UtilsB.java
public static void printA(){
System.out.println("print A");
}
public static void printB(){
System.out.println("print B");
}
Main.java
public static Main sMain = null;
public static void main(String[] args) {
sMain = new Main();
sMain.run();
}
private void run() {
ModelA modelA = new ModelA();
modelA.modelA(5);
UtilsA.printA();
}
//我们先不添加任何混淆参数,混淆之后的结果
src
-> a
-> a.java
private int a = 2;
public final void a(int i) {
System.out.println("print " + (this.a + 5));
}
-> defpackage
-> Main.java
private static Main a = null;
public static void main(String[] strArr) {
a = new Main();
new a().a(5);
System.out.println("print utila");
}对比一下混淆前和混淆后的 Jar 包内容
看到几个很显然的效果
- 没有被代码入口点调用到的类、方法都删除了。
- 定义的多个变量也都合并到一起了,甚至完全消失不见了。
- 很多方法也进行了合并。
- 除了代码入口点之外,留下来方法名和变量名全都改变了。
- 优化了代码,可以看到上面 public static Main sMain = null; 混淆完自动给改成了 private。
- 他还会自动把一部分方法优化为 final 的。
为什么 Main 这个类以及 main 方法没有被混淆呢?
在 ProGuard 默认生成的配置文件下有个条匹配规则
-keepclasseswithmembers public class * {
public static void main(java.lang.String[]);
}解释一下:匹配每个类里面的 main 方法为代码入口点,如果没有任何一个类有 main 方法。那么我们的上面的例子就是空的文件了,因为在压缩阶段就已经把所有代码全都删了。
main 方法是 Java 应用程序的入口方法,程序运行执行的第一个方法。
小结
经过这个小例子,除了预校验之外,其他特性我们都已经明显的看到了。概念也大概的懂了。恭喜你打怪升级成功,快去看看下一篇吧。


没有评论